百度飞桨(PaddlePaddle)安装
OCR 文字检测(Differentiable Binarization --- DB)
OCR的技术路线
PaddleHub 预训练模型的网络结构是 DB + CRNN, 可微的二值化模块(Differentiable Binarization,简称DB)
CRNN(Convolutional Recurrent Neural Network)即卷积递归神经网络, 是DCNN和RNN的组合
DB(Differentiable Binarization)是一种基于分割的文本检测算法。将二值化阈值加入训练中学习,可以获得更准确的检测边界,从而简化后处理流程。DB算法最终在5个数据集上达到了state-of-art的效果和性能
CRNN(Convolutional Recurrent Neural Network)即卷积递归神经网络,是DCNN和RNN的组合,专门用于识别图像中的序列式对象。与CTC loss配合使用,进行文字识别,可以直接从文本词级或行级的标注中学习,不需要详细的字符级的标注
安装库
Building wheel for opencv-python (pyproject.toml):https://www.cnblogs.com/vipsoft/p/17386638.html
# 安装 PaddlePaddle
python -m pip install paddlepaddle -i https://pypi.tuna.tsinghua.edu.cn/simple
# 安装 PaddleHub Mac 电脑上终端会感觉卡死的状态,可以添加 --verbose,查看进度
pip install paddlehub -i https://pypi.tuna.tsinghua.edu.cn/simple --verbose
# 该Module依赖于第三方库shapely、pyclipper,使用该Module之前,请先安装shapely、pyclipper
pip install shapely -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install pyclipper -i https://pypi.tuna.tsinghua.edu.cn/simple
定义待预测数据
将预测图片存放在一个文件中 picture.txt
./images/231242.jpg
./images/234730.jpg
测试输出
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
# 将预测图片存放在一个文件中(picture.txt)
with open('picture.txt', 'r') as f:
test_img_path=[]
for line in f:
test_img_path.append(line.strip())
# 显示图片
img1 = mpimg.imread(line.strip())
plt.figure(figsize=(10, 10))
plt.imshow(img1)
plt.axis('off')
plt.show()
print(test_img_path) # => ['images/231242.jpg', 'images/234730.jpg']
加载预训练模型
PaddleHub提供了以下文字识别模型:
移动端的超轻量模型:仅有8.1M,chinese_ocr_db_crnn_mobile
服务器端的精度更高模型:识别精度更高,chinese_ocr_db_crnn_server。
识别文字算法均采用CRNN(Convolutional Recurrent Neural Network)即卷积递归神经网络。其是DCNN和RNN的组合,专门用于识别图像中的序列式对象。与CTC loss配合使用,进行文字识别,可以直接从文本词级或行级的标注中学习,不需要详细的字符级的标注。该Module支持直接预测。 移动端与服务器端主要在于骨干网络的差异性,移动端采用MobileNetV3,服务器端采用ResNet50_vd
import paddlehub as hub
# 加载移动端预训练模型
# ocr = hub.Module(name="chinese_ocr_db_crnn_mobile")
# 服务端可以加载大模型,效果更好
ocr = hub.Module(name="chinese_ocr_db_crnn_server")
预测
PaddleHub对于支持一键预测的module,可以调用module的相应预测API,完成预测功能。
module 'numpy' has no attribute 'int'.: 解方法见:https://www.cnblogs.com/vipsoft/p/17385169.html
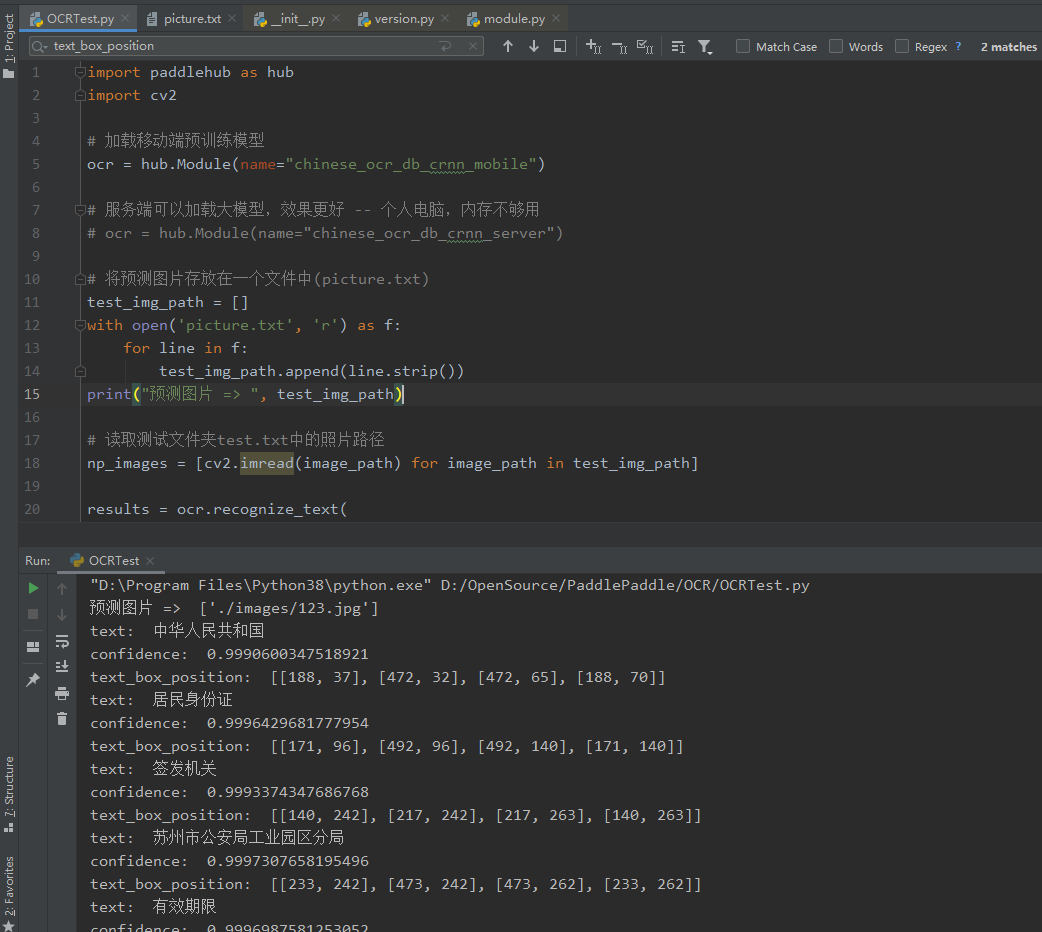
import paddlehub as hub
import cv2
# 加载移动端预训练模型
ocr = hub.Module(name="chinese_ocr_db_crnn_mobile")
# 服务端可以加载大模型,效果更好 -- 【个人电脑,内存不够用】
# ocr = hub.Module(name="chinese_ocr_db_crnn_server")
# 将预测图片存放在一个文件中(picture.txt)
test_img_path = []
with open('picture.txt', 'r') as f:
for line in f:
test_img_path.append(line.strip())
print("预测图片 => ", test_img_path)
# 读取测试文件夹test.txt中的照片路径
np_images = [cv2.imread(image_path) for image_path in test_img_path]
results = ocr.recognize_text(
images=np_images, # 图片数据,ndarray.shape 为 [H, W, C],BGR格式;
use_gpu=False, # 是否使用 GPU;若使用GPU,请先设置CUDA_VISIBLE_DEVICES环境变量
output_dir='ocr_result', # 图片的保存路径,默认设为 ocr_result;
visualization=True, # 是否将识别结果保存为图片文件;
box_thresh=0.5, # 检测文本框置信度的阈值;
text_thresh=0.5) # 识别中文文本置信度的阈值;
for result in results:
data = result['data']
save_path = result['save_path']
for infomation in data:
print('text: ', infomation['text'], '\nconfidence: ', infomation['confidence'], '\ntext_box_position: ', infomation['text_box_position'])
输出
"D:\Program Files\Python38\python.exe" D:/OpenSource/PaddlePaddle/OCR/OCRTest.py
预测图片 => ['./images/123.jpg']
text: 中华人民共和国
confidence: 0.9990600347518921
text_box_position: [[188, 37], [472, 32], [472, 65], [188, 70]]
text: 居民身份证
confidence: 0.9996429681777954
text_box_position: [[171, 96], [492, 96], [492, 140], [171, 140]]
text: 签发机关
confidence: 0.9993374347686768
text_box_position: [[140, 242], [217, 242], [217, 263], [140, 263]]
text: 苏州市公安局工业园区分局
confidence: 0.9997307658195496
text_box_position: [[233, 242], [473, 242], [473, 262], [233, 262]]
text: 有效期限
百度飞桨:https://aistudio.baidu.com/aistudio/projectdetail/507159




